
近年来 Spark 已经成为离线大数据处理引擎的事实标准,广泛用于数据仓库、数据湖、机器学习等领域。随着业务的快速发展,用户对计算资源的需求越来越大,除了增加物理资源之外,如何提高线上 Spark 作业的资源使用效率也是我们需解决的问题。
Spark内存模型详解※
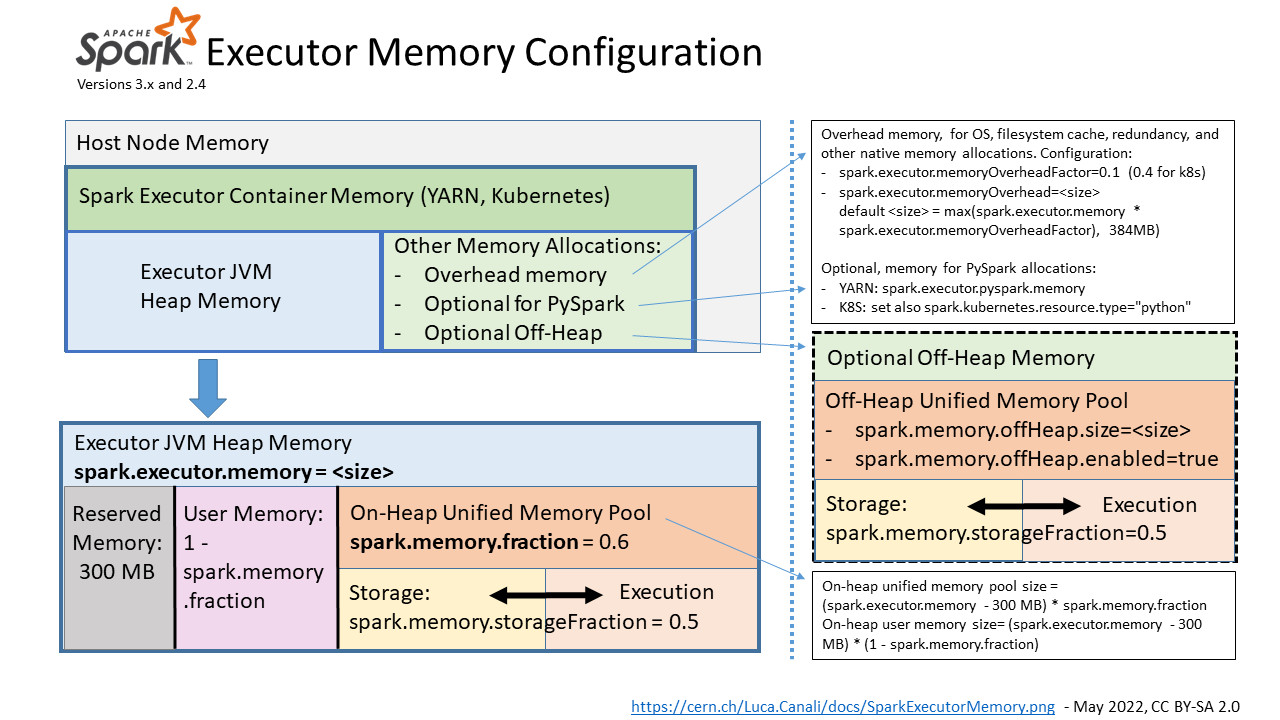
保留内存※
这是系统保留的内存,其大小是硬编码的。从 Spark 1.6.0 开始,它的值为 300MB,这意味着这 300MB 的 RAM 不参与 Spark 内存区域大小计算,并且如果不重新编译Spark 或设置spark.testing.reservedMemory,其大小不能以任何方式更改。
用户内存※
这是分配Spark Memory后剩余的内存池,用户可以完全按照自己的方式使用它。用户可以将自己的数据结构存储在其中,以用于 RDD 转换。
Spark Memory(统一内存)※
这是由 Apache Spark 管理的内存池。其大小可以通过以下公式计算:(Java 堆 – 保留内存 ) * spark.memory.fraction。例如,如果堆为 4GB,则该池的大小为 2004MB。整个池分为两个区域 –存储内存 和执行内存,它们之间的边界由spark.memory.storageFraction参数设置,默认值为 0.5。这种新内存管理方案的优点是该边界不是静态的,如果出现内存压力,边界就会移动,即一个区域可以通过借用另一个区域的空间来增长。
- 执行 ——用于混洗、连接、排序和聚合
- 存储 ——用于缓存数据分区和广播变量
执行内存往往比存储更 “短暂” 。每次操作后都会立即被清除,为下一个操作腾出空间。
在存储方面 ,两个主要函数处理数据的持久性-RDD的cache()和persist()。
Spark内存模型示例代码※
public class SparkMemoryCalculation {
private static final long MB = 1024 * 1024;
private static final long RESERVED_SYSTEM_MEMORY_BYTES = 300 * MB;
private static final double SparkMemoryStorageFraction = 0.5;
private static final double SparkMemoryFraction = 0.6;
public static void main(String[] args) {
// JVM -Xmx4g 指定
long systemMemory = Runtime.getRuntime().maxMemory();
long usableMemory = systemMemory - RESERVED_SYSTEM_MEMORY_BYTES;
long sparkMemory = convertDoubletLong(usableMemory * SparkMemoryFraction);
long userMemory = convertDoubletLong(usableMemory * (1 - SparkMemoryFraction));
long storageMemory = convertDoubletLong(sparkMemory * SparkMemoryStorageFraction);
long executionMemory = convertDoubletLong(sparkMemory * (1 - SparkMemoryStorageFraction));
printMemoryInMB("堆内存", systemMemory);
printMemoryInMB("保留内存", RESERVED_SYSTEM_MEMORY_BYTES);
printMemoryInMB("可用内存", usableMemory);
printMemoryInMB("用户内存", userMemory);
printMemoryInMB("统一内存", sparkMemory);
printMemoryInMB("存储内存", storageMemory);
printMemoryInMB("计算内存", executionMemory);
}
private static void printMemoryInMB(String type, long memory) {
System.out.println(type + " \t=\t" + (memory / MB) + " MB");
}
private static Long convertDoubletLong(double val) {
return new Double(val).longValue();
}
}
Spark指标※
在当前治理过程中主要使用了以下Executor指标
JVMHeapMemory 用于对象分配的堆的峰值内存使用量,返回的内存使用量中的已用内存量是活动对象和尚未收集的垃圾对象(如果有)占用的内存量。
case object JVMHeapMemory extends SingleValueExecutorMetricType { override private[spark] def getMetricValue(memoryManager: MemoryManager): Long = { ManagementFactory.getMemoryMXBean.getHeapMemoryUsage().getUsed() } }- OnHeapExecutionMemory 正在使用的堆执行内存的峰值(以字节为单位)
- OnHeapStorageMemory 正在使用的堆存储内存的峰值(以字节为单位)。
- totalDuration JVM 在此执行器中执行任务所用的时间。该值以毫秒为单位。
- totalGCTime 此执行器中 JVM 进行垃圾回收所用的时间总计。该值以毫秒为单位。
诊断规则※
基于任务最近的运行指标进行分析,并尝试给出建议值
内存资源利用率低※
方案一:
使用 JVMHeapMemory 指标
MAX(JVMHeapMemory ) * 1.2 / 0.88
基于运行历史中JVMHeapMemory 最大值上调20% , Runtime.getRuntime().maxMemory()约等于JVM -Xmx * 0.88
建议值取整到Yarn容器内存的倍数,避免资源浪费
方案二:
使用OnHeapExecutionMemory + OnHeapStorageMemory 指标
(MAX(OnHeapExecutionMemory + OnHeapStorageMemory ) / 0.6 * 1.2 + 300M) / 0.88
0.6 = spark.memory.fraction
1.2 = 资源上调20%
300M = 保留内存
0.88 = Runtime.getRuntime().maxMemory()约等于JVM -Xmx * 0.88
建议值取整到Yarn容器内存的倍数,避免资源浪费
GC过长※
使用totalDuration + totalGCTime 指标
totalGCTime >= totalDuration * 0.1
Spark UI页面中将GC时长占比10%的Executor进行标红处理
参考资料
