
在编写 Flink 的程序的时候,核心的要点是构造出数据处理的拓扑结构,即任务执行逻辑的 DAG。我们先来看一下 Flink 任务的拓扑在逻辑上是怎么保存的。
StreamGraph 相关的代码主要在 org.apache.flink.streaming.api.graph 包中。构造StreamGraph的入口函数是 getStreamGraphGenerator(transformations).generate()。该函数会由触发程序执行的方法StreamExecutionEnvironment.execute()调用到。也就是说 StreamGraph 是在 Client 端构造的,这也意味着我们可以在本地通过调试观察 StreamGraph 的构造过程。
注:本文比较偏源码分析,所有代码都是基于 flink-1.20.0版本分析
StreamExecutionEnvironment※
StreamExecutionEnvironment 是 Flink 在流模式下任务执行的上下文,也是我们编写 Flink 程序的入口。根据具体的执行环境不同,StreamExecutionEnvironment 有不同的具体实现类,如 LocalStreamEnvironment, RemoteStreamEnvironment等。StreamExecutionEnvironment 也提供了用来配置默认并行度、Checkpointing 等机制的方法,这些配置主要都保存在 ExecutionConfig和 CheckpointConfig中。我们现在先只关注拓扑结构的产生。
通常一个 Flink 任务是按照下面的流程来编写处理逻辑的:
env.fromSequence(1, 4).map(line -> line + 1).shuffle().filter(line -> line > 0).print();添加数据源后获得 DataStream, 之后通过不同的算子不停地在 DataStream 上实现转换过滤等逻辑,最终将结果输出到 DataSink 中。
在 StreamExecutionEnvironment 内部使用一个 List<Transformation<?>> transformations 来保留生成 DataStream 的所有转换。
Transformation※
Transformation 代表了生成 DataStream 的操作,每一个 DataStream 的底层都有对应的一个 Transformation。在 DataStream 上面通过 map 等算子不断进行转换,就得到了由 Transformation构成的图。当需要执行的时候,底层的这个图就会被转换成 StreamGraph 。
比如 DataStream.map源码如下,其中SingleOutputStreamOperator为DataStream的子类:
//DataStream#map
public <R> SingleOutputStreamOperator<R> map(
MapFunction<T, R> mapper, TypeInformation<R> outputType) {
// 返回一个新的DataStream,SteramMap 为 StreamOperator 的实现类
return transform("Map", outputType, new StreamMap<>(clean(mapper)));
}
// DataStream#doTransform
protected <R> SingleOutputStreamOperator<R> doTransform(
String operatorName,
TypeInformation<R> outTypeInfo,
StreamOperatorFactory<R> operatorFactory) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
// 新的transformation会连接上当前DataStream中的transformation,从而构建成一棵树
OneInputTransformation<T, R> resultTransform =
new OneInputTransformation<>(
this.transformation,
operatorName,
operatorFactory,
outTypeInfo,
environment.getParallelism(),
false);
@SuppressWarnings({"unchecked", "rawtypes"})
SingleOutputStreamOperator<R> returnStream =
new SingleOutputStreamOperator(environment, resultTransform);
// 所有的transformation都会存到 env 中,调用execute时遍历该list生成StreamGraph
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}从上方代码可以了解到,map转换将用户自定义的函数MapFunction包装到StreamMap这个Operator中,再将StreamMap包装到OneInputTransformation,最后该transformation存到env中,当调用env.execute时,遍历其中的transformation集合构造出StreamGraph。其分层实现如下图所示:
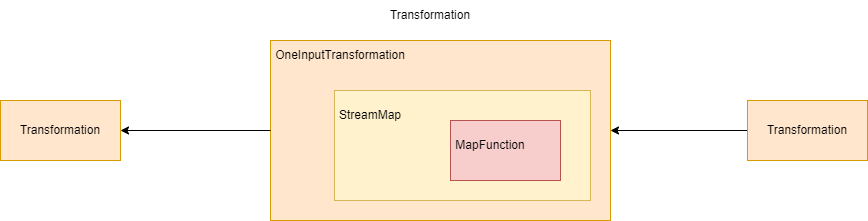
Transformation在运行时并不一定对应着一个物理转换操作,有一些操作只是逻辑层面上的,比如 partitionCustom/shuffle 等。
每一个 Transformation都有一个关联的 Id,这个 Id 是全局递增的。除此以外,还有 uid, slotSharingGroup, parallelism等信息。
Transformation有很多具体的子类,如SourceTransformation、 OneInputTransformation、TwoInputTransformation、SideOutputTransformation、 SinkTransformation 等等,这些分别对应了DataStream 上的不同转换操作。

由于 Transformation中通常保留了其前向的 Transformation,即其输入,因此可以据此还原出 DAG 的拓扑结构。
// OneInputTransformation
public OneInputTransformation(
Transformation<IN> input,
String name,
OneInputStreamOperator<IN, OUT> operator,
TypeInformation<OUT> outputType,
int parallelism) {
this(input, name, SimpleOperatorFactory.of(operator), outputType, parallelism);
}
// TwoInputTransformation
public TwoInputTransformation(
Transformation<IN1> input1,
Transformation<IN2> input2,
String name,
TwoInputStreamOperator<IN1, IN2, OUT> operator,
TypeInformation<OUT> outputType,
int parallelism) {
this(input1, input2, name, SimpleOperatorFactory.of(operator), outputType, parallelism);
}
DataStream※
一个 DataStream 就表征了由同一种类型元素构成的数据流。通过对 DataStream 应用 map/filter 等操作,可以将一个 DataStream 转换为另一个 DataStream,这个转换的过程就是根据不同的操作生成不同的 Transformation,并将其加入 StreamExecutionEnvironment 的 transformations 列表中。
例如:
//构造 Transformation
OneInputTransformation<T, R> resultTransform =
new OneInputTransformation<>(
this.transformation,
operatorName,
operatorFactory,
outTypeInfo,
environment.getParallelism(),
false);
@SuppressWarnings({"unchecked", "rawtypes"})
SingleOutputStreamOperator<R> returnStream =
new SingleOutputStreamOperator(environment, resultTransform);
//加入到 StreamExecutionEnvironment 的列表中
getExecutionEnvironment().addOperator(resultTransform);DataStream 的子类包括 SideOutputDataStream、 DataStreamSource 、KeyedStream、SingleOutputStreamOperator。这里要吐槽一下 SingleOutputStreamOperator 的这个类的命名,太容易和 StreamOperator 混淆了。StreamOperator 的介绍见下一小节。

除了 DataStream 及其子类以外,其它的表征数据流的类还有 ConnectedStreams (两个流连接在一起)、 WindowedStream、AllWindowedStream 。这些数据流之间的转换可以参考 Flink 的官方文档。
StreamOperator※
在操作 DataStream 的时候,比如 DataStream#map 等,会要求我们提供一个自定义的处理函数。那么这些信息时如何保存在 Transformation中的呢?这里就要引入一个新的接口 StreamOperator。
StreamOperator 定义了对一个具体的算子的生命周期的管理,包括:
void open() throws Exception;
void close() throws Exception;
//状态管理
OperatorSnapshotFutures snapshotState(
long checkpointId,
long timestamp,
CheckpointOptions checkpointOptions,
CheckpointStreamFactory storageLocation)
throws Exception;
void initializeState(StreamTaskStateInitializer streamTaskStateManager) throws Exception;
//其它方法暂时省略注:
- setup方法移到了SetupableStreamOperator接口中
StreamOperator 的两个子接口 OneInputStreamOperator 和 TwoInputStreamOperator 则提供了操作数据流中具体元素的方法,而 AbstractUdfStreamOperator 这个抽象子类则提供了自定义处理函数对应的算子的基本实现:
//OneInputStreamOperator
void processElement(StreamRecord<IN> element) throws Exception;
void processWatermark(Watermark mark) throws Exception;
void processLatencyMarker(LatencyMarker latencyMarker) throws Exception;
//TwoInputStreamOperator
void processElement1(StreamRecord<IN1> element) throws Exception;
void processElement2(StreamRecord<IN2> element) throws Exception;
//AbstractUdfStreamOperator 接受一个用户自定义的处理函数
public AbstractUdfStreamOperator(F userFunction) {
this.userFunction = requireNonNull(userFunction);
checkUdfCheckpointingPreconditions();
}注:
- 方法定义到了Input接口中,OneInputStreamOperator 继承了它,所以目前在OneInputStreamOperator 中是不能看到processElement等方法
至于具体到诸如 map/fliter 等操作对应的 StreamOperator,基本都是在 AbstractUdfStreamOperator 的基础上实现的。以 StreamMap 为例:
public class StreamMap<IN, OUT> extends AbstractUdfStreamOperator<OUT, MapFunction<IN, OUT>>
implements OneInputStreamOperator<IN, OUT> {
private static final long serialVersionUID = 1L;
public StreamMap(MapFunction<IN, OUT> mapper) {
super(mapper);
chainingStrategy = ChainingStrategy.ALWAYS;
}
@Override
public void processElement(StreamRecord<IN> element) throws Exception {
output.collect(element.replace(userFunction.map(element.getValue())));
}
}由此,通过 DataStream –> Transformation–> StreamOperator 这样的依赖关系,就可以完成 DataStream 的转换,并且保留数据流和应用在流上的算子之间的关系。
StreamGraph※
StreamGraphGenerator 会基于 StreamExecutionEnvironment 的 transformations 列表来生成 StreamGraph。
在遍历 List<Transformation<?>> 生成 StreamGraph 的时候,会递归调用StreamGraphGenerator#transform方法。对于每一个 Transformation, 确保当前其上游已经完成转换。transformations 被转换为 StreamGraph 中的节点 StreamNode,并为上下游节点添加边 StreamEdge。
// StreamExecutionEnvironment#getStreamGraph
// 构造 StreamGraph 入口函数
private StreamGraph getStreamGraph(List<Transformation<?>> transformations) {
synchronizeClusterDatasetStatus();
return getStreamGraphGenerator(transformations).generate();
}
//StreamGraphGenerator#generate
public StreamGraph generate() {
streamGraph =
new StreamGraph(
configuration, executionConfig, checkpointConfig, savepointRestoreSettings);
// 判断是否应以批处理模式执行
shouldExecuteInBatchMode = shouldExecuteInBatchMode();
//配置
configureStreamGraph(streamGraph);
alreadyTransformed = new IdentityHashMap<>();
for (Transformation<?> transformation : transformations) {
// 对转换树的每个transformation进行转换
transform(transformation);
}
streamGraph.setSlotSharingGroupResource(slotSharingGroupResources);
//缓解批处理作业中应用细粒度资源管理时,可能会出现资源死锁情况
// 目前需要用户手动设置成开启阻塞
setFineGrainedGlobalStreamExchangeMode(streamGraph);
// 判断是否应禁用未对齐检查点
for (StreamNode node : streamGraph.getStreamNodes()) {
if (node.getInEdges().stream().anyMatch(this::shouldDisableUnalignedCheckpointing)) {
for (StreamEdge edge : node.getInEdges()) {
edge.setSupportsUnalignedCheckpoints(false);
}
}
}
final StreamGraph builtStreamGraph = streamGraph;
alreadyTransformed.clear();
alreadyTransformed = null;
streamGraph = null;
return builtStreamGraph;
}
// StreamGraphGenerator#transform
// 转换一个 Transformation.
private Collection<Integer> transform(Transformation<?> transform) {
// 由于是递归调用的,可能已经完成了转换
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
LOG.debug("Transforming " + transform);
if (transform.getMaxParallelism() <= 0) {
// if the max parallelism hasn't been set, then first use the job wide max parallelism
// from the ExecutionConfig.
int globalMaxParallelismFromConfig = executionConfig.getMaxParallelism();
if (globalMaxParallelismFromConfig > 0) {
transform.setMaxParallelism(globalMaxParallelismFromConfig);
}
}
transform
.getSlotSharingGroup()
.ifPresent(
slotSharingGroup -> {
// 提取资源规格
final ResourceSpec resourceSpec =
SlotSharingGroupUtils.extractResourceSpec(slotSharingGroup);
if (!resourceSpec.equals(ResourceSpec.UNKNOWN)) {
slotSharingGroupResources.compute(
slotSharingGroup.getName(),
(name, profile) -> {
if (profile == null) {
return ResourceProfile.fromResourceSpec(
resourceSpec, MemorySize.ZERO);
} else if (!ResourceProfile.fromResourceSpec(
resourceSpec, MemorySize.ZERO)
.equals(profile)) {
throw new IllegalArgumentException(
"The slot sharing group "
+ slotSharingGroup.getName()
+ " has been configured with two different resource spec.");
} else {
return profile;
}
});
}
});
// call at least once to trigger exceptions about MissingTypeInfo
// 至少调用一次以触发有关 MissingTypeInfo 的异常
transform.getOutputType();
@SuppressWarnings("unchecked")
final TransformationTranslator<?, Transformation<?>> translator =
(TransformationTranslator<?, Transformation<?>>)
translatorMap.get(transform.getClass());
Collection<Integer> transformedIds;
// 进行转换
if (translator != null) {
transformedIds = translate(translator, transform);
} else {
transformedIds = legacyTransform(transform);
}
// need this check because the iterate transformation adds itself before
// transforming the feedback edges
//需要此检查,因为迭代转换在转换反馈边缘之前添加了自身
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
return transformedIds;
}
// StreamGraphGenerator#translate
private Collection<Integer> translate(
final TransformationTranslator<?, Transformation<?>> translator,
final Transformation<?> transform) {
checkNotNull(translator);
checkNotNull(transform);
//首先确保上游节点完成转换
final List<Collection<Integer>> allInputIds = getParentInputIds(transform.getInputs());
// the recursive call might have already transformed this
// 由于是递归调用的,可能已经完成了转换
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
//确定资源共享组,用户如果没有指定,默认是default
final String slotSharingGroup =
determineSlotSharingGroup(
transform.getSlotSharingGroup().isPresent()
? transform.getSlotSharingGroup().get().getName()
: null,
allInputIds.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList()));
final TransformationTranslator.Context context =
new ContextImpl(this, streamGraph, slotSharingGroup, configuration);
// 调用TransformationTranslator
return shouldExecuteInBatchMode
? translator.translateForBatch(transform, context)
: translator.translateForStreaming(transform, context);
}
对于不同类型的 transformations ,分别调用对应的转换方法,以 最典型的 OneInputTransformationTranslator为例:
// AbstractOneInputTransformationTranslator#translateInternal
protected Collection<Integer> translateInternal(
final Transformation<OUT> transformation,
final StreamOperatorFactory<OUT> operatorFactory,
final TypeInformation<IN> inputType,
@Nullable final KeySelector<IN, ?> stateKeySelector,
@Nullable final TypeInformation<?> stateKeyType,
final Context context) {
checkNotNull(transformation);
checkNotNull(operatorFactory);
checkNotNull(inputType);
checkNotNull(context);
final StreamGraph streamGraph = context.getStreamGraph();
final String slotSharingGroup = context.getSlotSharingGroup();
final int transformationId = transformation.getId();
final ExecutionConfig executionConfig = streamGraph.getExecutionConfig();
//向 StreamGraph 中添加 Operator, 这一步会生成对应的 StreamNode
streamGraph.addOperator(
transformationId,
slotSharingGroup,
transformation.getCoLocationGroupKey(),
operatorFactory,
inputType,
transformation.getOutputType(),
transformation.getName());
if (stateKeySelector != null) {
TypeSerializer<?> keySerializer =
stateKeyType.createSerializer(executionConfig.getSerializerConfig());
streamGraph.setOneInputStateKey(transformationId, stateKeySelector, keySerializer);
}
int parallelism =
transformation.getParallelism() != ExecutionConfig.PARALLELISM_DEFAULT
? transformation.getParallelism()
: executionConfig.getParallelism();
streamGraph.setParallelism(
transformationId, parallelism, transformation.isParallelismConfigured());
streamGraph.setMaxParallelism(transformationId, transformation.getMaxParallelism());
final List<Transformation<?>> parentTransformations = transformation.getInputs();
checkState(
parentTransformations.size() == 1,
"Expected exactly one input transformation but found "
+ parentTransformations.size());
//依次连接到上游节点,创建 StreamEdge
for (Integer inputId : context.getStreamNodeIds(parentTransformations.get(0))) {
streamGraph.addEdge(inputId, transformationId, 0);
}
if (transformation instanceof PhysicalTransformation) {
streamGraph.setSupportsConcurrentExecutionAttempts(
transformationId,
((PhysicalTransformation<OUT>) transformation)
.isSupportsConcurrentExecutionAttempts());
}
return Collections.singleton(transformationId);
}
接着看一看 StreamGraph 中对应的添加节点和边的方法:
protected StreamNode addNode(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
Class<? extends TaskInvokable> vertexClass,
@Nullable StreamOperatorFactory<?> operatorFactory,
String operatorName) {
if (streamNodes.containsKey(vertexID)) {
throw new RuntimeException("Duplicate vertexID " + vertexID);
}
StreamNode vertex =
new StreamNode(
vertexID,
slotSharingGroup,
coLocationGroup,
operatorFactory,
operatorName,
vertexClass);
//创建 StreamNode,这里保存了 StreamOperator 和 vertexClass 信息
streamNodes.put(vertexID, vertex);
return vertex;
}在 StreamNode 中,保存了对应的 StreamOperator (从 Transformation得到),并且还引入了变量 jobVertexClass 来表示该节点在 TaskManager 中运行时的实际任务类型。
private final Class<? extends TaskInvokable> jobVertexClass;TaskInvokable是所有可以在 TaskManager 中运行的任务的接口基础类,包括流式任务和批任务。StreamTask 是所有流式任务的基础类,其具体的子类包括 SourceStreamTask(已废弃), OneInputStreamTask, TwoInputStreamTask等。
对于一些不包含物理转换操作的 Transformation,如 partitionCustom,并不会生成 StreamNode,而是生成一个带有特定属性的虚拟节点。当添加一条有虚拟节点指向下游节点的边时,会找到虚拟节点上游的物理节点,在两个物理节点之间添加边,并把虚拟转换操作的属性附着上去。
以 PartitionTransformation为例
// PartitionTransformationTranslator#translateInternal
private Collection<Integer> translateInternal(
final PartitionTransformation<OUT> transformation,
final Context context,
boolean supportsBatchExchange) {
checkNotNull(transformation);
checkNotNull(context);
final StreamGraph streamGraph = context.getStreamGraph();
final List<Transformation<?>> parentTransformations = transformation.getInputs();
checkState(
parentTransformations.size() == 1,
"Expected exactly one input transformation but found "
+ parentTransformations.size());
final Transformation<?> input = parentTransformations.get(0);
List<Integer> resultIds = new ArrayList<>();
StreamExchangeMode exchangeMode = transformation.getExchangeMode();
// StreamExchangeMode#BATCH has no effect in streaming mode so we can safely reset it to
// UNDEFINED and let Flink decide on the best exchange mode.
if (!supportsBatchExchange && exchangeMode == StreamExchangeMode.BATCH) {
exchangeMode = StreamExchangeMode.UNDEFINED;
}
for (Integer inputId : context.getStreamNodeIds(input)) {
final int virtualId = Transformation.getNewNodeId();
//添加虚拟的 Partition 节点
streamGraph.addVirtualPartitionNode(
inputId, virtualId, transformation.getPartitioner(), exchangeMode);
resultIds.add(virtualId);
}
return resultIds;
}
// StreamGraph#addVirtualPartitionNode
public void addVirtualPartitionNode(
Integer originalId,
Integer virtualId,
StreamPartitioner<?> partitioner,
StreamExchangeMode exchangeMode) {
if (virtualPartitionNodes.containsKey(virtualId)) {
throw new IllegalStateException(
"Already has virtual partition node with id " + virtualId);
}
//添加一个虚拟节点,后续添加边的时候会连接到实际的物理节点
virtualPartitionNodes.put(virtualId, new Tuple3<>(originalId, partitioner, exchangeMode));
}前面提到,在每一个物理节点的转换上,会调用 StreamGraph#addEdge 在输入节点和当前节点之间建立边的连接:
// StreamGraph#addEdgeInternal
private void addEdgeInternal(
Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?> partitioner,
List<String> outputNames,
OutputTag outputTag,
StreamExchangeMode exchangeMode,
IntermediateDataSetID intermediateDataSetId) {
//先判断是不是虚拟节点上的边,如果是,则找到虚拟节点上游对应的物理节点
//在两个物理节点之间添加边,并把对应的 StreamPartitioner,或者 OutputTag 等补充信息添加到StreamEdge中
if (virtualSideOutputNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSideOutputNodes.get(virtualId).f0;
if (outputTag == null) {
outputTag = virtualSideOutputNodes.get(virtualId).f1;
}
addEdgeInternal(
upStreamVertexID,
downStreamVertexID,
typeNumber,
partitioner,
null,
outputTag,
exchangeMode,
intermediateDataSetId);
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
exchangeMode = virtualPartitionNodes.get(virtualId).f2;
addEdgeInternal(
upStreamVertexID,
downStreamVertexID,
typeNumber,
partitioner,
outputNames,
outputTag,
exchangeMode,
intermediateDataSetId);
} else {
//创建实际的边缘
createActualEdge(
upStreamVertexID,
downStreamVertexID,
typeNumber,
partitioner,
outputTag,
exchangeMode,
intermediateDataSetId);
}
}
//StreamGraph#createActualEdge
private void createActualEdge(
Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?> partitioner,
OutputTag outputTag,
StreamExchangeMode exchangeMode,
IntermediateDataSetID intermediateDataSetId) {
//两个物理节点
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
// If no partitioner was specified and the parallelism of upstream and downstream
// operator matches use forward partitioning, use rebalance otherwise.
//如果未指定分区器,并且上游和下游算子的并行度匹配使用前向分区,则使用重新平衡,否则使用重新平衡。
if (partitioner == null
&& upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner =
dynamic ? new ForwardForUnspecifiedPartitioner<>() : new ForwardPartitioner<>();
} else if (partitioner == null) {
partitioner = new RebalancePartitioner<Object>();
}
if (partitioner instanceof ForwardPartitioner) {
if (upstreamNode.getParallelism() != downstreamNode.getParallelism()) {
if (partitioner instanceof ForwardForConsecutiveHashPartitioner) {
partitioner =
((ForwardForConsecutiveHashPartitioner<?>) partitioner)
.getHashPartitioner();
} else {
throw new UnsupportedOperationException(
"Forward partitioning does not allow "
+ "change of parallelism. Upstream operation: "
+ upstreamNode
+ " parallelism: "
+ upstreamNode.getParallelism()
+ ", downstream operation: "
+ downstreamNode
+ " parallelism: "
+ downstreamNode.getParallelism()
+ " You must use another partitioning strategy, such as broadcast, rebalance, shuffle or global.");
}
}
}
if (exchangeMode == null) {
exchangeMode = StreamExchangeMode.UNDEFINED;
}
/**
* Just make sure that {@link StreamEdge} connecting same nodes (for example as a result of
* self unioning a {@link DataStream}) are distinct and unique. Otherwise it would be
* difficult on the {@link StreamTask} to assign {@link RecordWriter}s to correct {@link
* StreamEdge}.
*/
//只需确保连接相同的节点
int uniqueId = getStreamEdges(upstreamNode.getId(), downstreamNode.getId()).size();
//创建 StreamEdge,保留了 StreamPartitioner 等属性
StreamEdge edge =
new StreamEdge(
upstreamNode,
downstreamNode,
typeNumber,
partitioner,
outputTag,
exchangeMode,
uniqueId,
intermediateDataSetId);
//分别将StreamEdge添加到上游节点和下游节点
getStreamNode(edge.getSourceId()).addOutEdge(edge);
getStreamNode(edge.getTargetId()).addInEdge(edge);
}这样通过 StreamNode 和 StreamEdge ,就得到了 DAG 中的所有节点和边,以及它们之间的连接关系,拓扑结构也就建立了。
小结※
本文简单分析了从 DataStream API 到 StreamGraph 的过程。 StreamGraph 是 Flink 任务最接近用户逻辑的 DAG 表示,后面到具体执行的时候还会进行一系列转换,我们在后续的文章中再逐一加以分析。
参考资料:
