
前面的文章我们介绍了 StreamGraph 的生成,这个实际上只对应 Flink 作业在逻辑上的执行计划图。Flink 会进一步对 StreamGraph 进行转换,得到另一个执行计划图,即 JobGraph。以此段代码为例,
env.fromData(1, 2, 3, 4).map(line -> line + 1).shuffle().filter(line -> line > 0).print();转换图如下图所示:
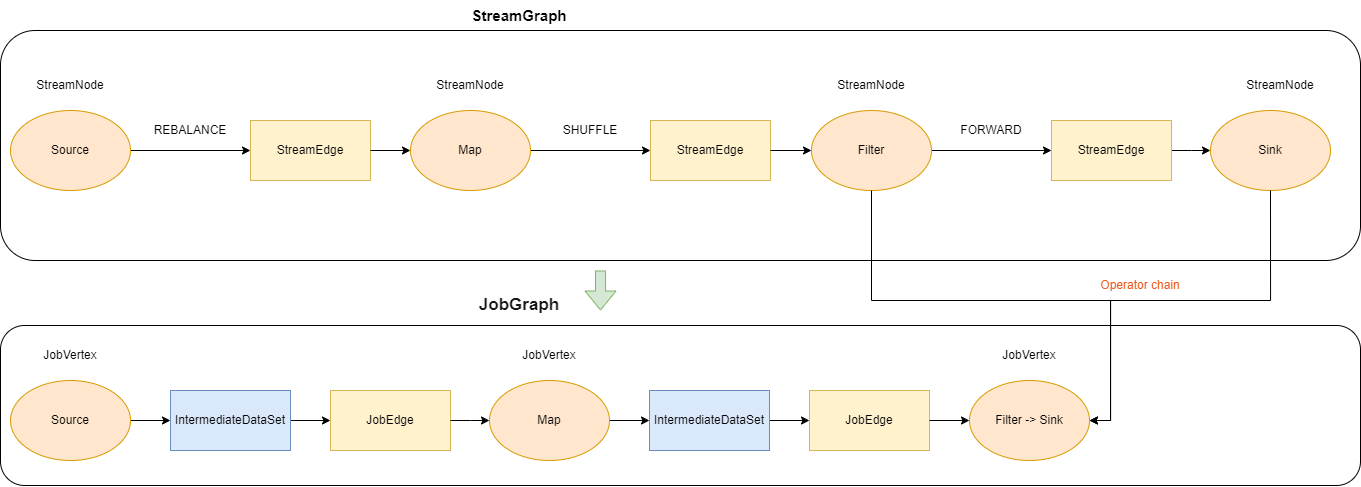
StreamGraph 和 JobGraph 都是在 Client 端生成的,也就是说我们可以在 IDE 中通过断点调试观察 StreamGraph 和 JobGraph 的生成过程。
JobGraph 的相关数据结构主要在 org.apache.flink.runtime.jobgraph 包中。构造 JobGraph 的代码主要集中在 StreamingJobGraphGenerator类中,入口函数是 StreamingJobGraphGenerator.createJobGraph()。
JobVertex※
在 StreamGraph 中,每一个算子(Operator) 对应了图中的一个节点(StreamNode)。StreamGraph 会被进一步优化,将多个符合条件的节点串联(Chain) 在一起形成一个节点,从而减少数据在不同节点之间流动所产生的序列化、反序列化、网络传输的开销。多个算子被 chain 在一起的形成的节点在 JobGraph 中对应的就是 JobVertex。
每个 JobVertex 都会对应一个可序列化的 StreamConfig, 用来发送给 JobManager 和 TaskManager。最后在 TaskManager 中起 Task 时,需要从这里面反序列化出所需要的配置信息, 其中就包括了含有用户代码的StreamOperator。
每个 JobVertex 中包含一个或多个 Operators。 JobVertex 的主要成员变量包括
/**
* The IDs of all operators contained in this vertex.
*
* <p>The ID pairs are stored depth-first post-order; for the forking chain below the ID's would
* be stored as [D, E, B, C, A].
*
* <pre>
* A - B - D
* \ \
* C E
* </pre>
*
* <p>This is the same order that operators are stored in the {@code StreamTask}.
*/
// 此顶点中包含的所有运算符的id 按深度优先后序存储
private final List<OperatorIDPair> operatorIDs;
/** Produced data sets, one per writer. */
// 生成的数据集
private final Map<IntermediateDataSetID, IntermediateDataSet> results = new LinkedHashMap<>();
/** List of edges with incoming data. One per Reader. */
//带有传入数据的边列表
private final List<JobEdge> inputs = new ArrayList<>();
/**
* The intermediateDataSetId of the cached intermediate dataset that the job vertex consumes.
*/
// 中间数据集ID
private final List<IntermediateDataSetID> intermediateDataSetIdsToConsume = new ArrayList<>();其输入是 JobEdge 列表, 输出是 IntermediateDataSet 列表。
JobEdge※
在 StramGraph 中,StreamNode 之间是通过 StreamEdge 建立连接的。在 JobEdge 中,对应的是 JobEdge 。
和 StreamEdge 中同时保留了源节点和目标节点 (sourceId 和 targetId)不同,在 JobEdge 中只有源节点的信息。由于 JobVertex 中保存了所有输入的 JobEdge 的信息,因而同样可以在两个节点之间建立连接。更确切地说,JobEdge 是和节点的输出结果相关联的,我们看下 JobEdge 主要的成员变量:
/** The vertex connected to this edge. */
// 与这条边相连的顶点
private final JobVertex target;
/** The distribution pattern that should be used for this job edge. */
// 决定了在上游节点(生产者)的子任务和下游节点(消费者)之间的连接模式
private final DistributionPattern distributionPattern;
/** The data set at the source of the edge, may be null if the edge is not yet connected. */
private final IntermediateDataSet source;
IntermediateDataSet※
JobVertex 产生的数据被抽象为 IntermediateDataSet, 字面意思为中间数据集,这个很容易理解。前面提到,JobEdge 是和节点的输出结果相关联的,其实就是指可以把 JobEdge 看作是 IntermediateDataSet 的消费者,那么 JobVertex 自然就是生产者了。
// 标识符
private final IntermediateDataSetID id;
//产生这个数据集的操作
private final JobVertex producer;
// All consumers must have the same partitioner and parallelism
// 所有消费者必须具有相同的分区器和并行性
private final List<JobEdge> consumers = new ArrayList<>();
// The type of partition to use at runtime
//运行时要使用的分区类型
private final ResultPartitionType resultType;
// 分布模式
private DistributionPattern distributionPattern;
其中 ResultPartitionType 表示中间结果的类型,说起来有点抽象,我们看下属性就明白了:
/**
* Can this result partition be consumed by multiple downstream consumers for multiple times.
*/
private final boolean isReconsumable;
/** Does this partition use a limited number of (network) buffers? */
private final boolean isBounded;
/** This partition will not be released after consuming if 'isPersistent' is true. */
private final boolean isPersistent;
private final ConsumingConstraint consumingConstraint;
private final ReleaseBy releaseBy;这个要结合 Flink 任务运行时的内存管理机制来看,在后面的文章再进行分析。目前在 Stream 模式下使用的类型是PIPELINED_BOUNDED(false, true, false, ConsumingConstraint.MUST_BE_PIPELINED, ReleaseBy.UPSTREAM)
StreamConfig※
对于每一个 StreamOperator, 也就是 StreamGraph 中的每一个 StreamNode, 在生成 JobGraph 的过程中 StreamingJobGraphGenerator 都会创建一个对应的 StreamConfig。
StreamConfig 中保存了这个算子(operator) 在运行是需要的所有配置信息,这些信息都是通过 key/value 的形式存储在 Configuration 中的。例如:
//保存StreamOperator信息
@VisibleForTesting
public void setStreamOperator(StreamOperator<?> operator) {
setStreamOperatorFactory(SimpleOperatorFactory.of(operator));
}
public void setStreamOperatorFactory(StreamOperatorFactory<?> factory) {
if (factory != null) {
toBeSerializedConfigObjects.put(SERIALIZED_UDF, factory);
toBeSerializedConfigObjects.put(SERIALIZED_UDF_CLASS, factory.getClass());
}
}
public void setChainedOutputs(List<StreamEdge> chainedOutputs) {
toBeSerializedConfigObjects.put(CHAINED_OUTPUTS, chainedOutputs);
}
public void setOperatorNonChainedOutputs(List<NonChainedOutput> nonChainedOutputs) {
toBeSerializedConfigObjects.put(OP_NONCHAINED_OUTPUTS, nonChainedOutputs);
}
public void setInPhysicalEdges(List<StreamEdge> inEdges) {
toBeSerializedConfigObjects.put(IN_STREAM_EDGES, inEdges);
}
//......
从 StreamGraph 到 JobGraph※
从 StreamGraph 到 JobGraph 的转换入口在 StreamingJobGraphGenerator 中。
首先来看下 StreamingJobGraphGenerator 的成员变量和入口函数:
// id -> JobVertex
private final Map<Integer, JobVertex> jobVertices;
// 已经构建的JobVertex的id集合
private final Collection<Integer> builtVertices;
// 物理边集合(排除了chain内部的边), 按创建顺序排序
private final List<StreamEdge> physicalEdgesInOrder;
// 保存chain信息,部署时用来构建 OperatorChain,startNodeId -> (currentNodeId -> StreamConfig)
private final Map<Integer, Map<Integer, StreamConfig>> chainedConfigs;
// 所有节点的配置信息,id -> StreamConfig
private final Map<Integer, StreamConfig> vertexConfigs;
// 保存每个节点的名字,id -> chainedName
private final Map<Integer, String> chainedNames;
//用于计算hash值的算法
private final StreamGraphHasher defaultStreamGraphHasher;
private final List<StreamGraphHasher> legacyStreamGraphHashers;
//.....
// 根据 StreamGraph,生成 JobGraph
private JobGraph createJobGraph() {
preValidate();
jobGraph.setJobType(streamGraph.getJobType());
jobGraph.setDynamic(streamGraph.isDynamic());
jobGraph.enableApproximateLocalRecovery(
streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
// 广度优先遍历 StreamGraph 并且为每个SteamNode生成hash,hash值将被用于 JobVertexId 中
// 保证如果提交的拓扑没有改变,则每次生成的hash都是一样的
Map<Integer, byte[]> hashes =
defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
//生成旧版本哈希以实现向后兼容性
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
// 最重要的函数,生成JobVertex,JobEdge等,并尽可能地将多个节点chain在一起
setChaining(hashes, legacyHashes);
if (jobGraph.isDynamic()) {
//如有必要,为动态图设置顶点并行性
setVertexParallelismsForDynamicGraphIfNecessary();
}
// Note that we set all the non-chainable outputs configuration here because the
// "setVertexParallelismsForDynamicGraphIfNecessary" may affect the parallelism of job
// vertices and partition-reuse
final Map<Integer, Map<StreamEdge, NonChainedOutput>> opIntermediateOutputs =
new HashMap<>();
//设置所有运算符非链式输出配置
setAllOperatorNonChainedOutputsConfigs(opIntermediateOutputs);
//设置所有顶点非链接输出配置
setAllVertexNonChainedOutputsConfigs(opIntermediateOutputs);
// 将每个JobVertex的入边集合也序列化到该JobVertex的StreamConfig中
// (出边集合已经在setChaining的时候写入了)
setPhysicalEdges();
//标记支持并发执行尝试
markSupportingConcurrentExecutionAttempts();
//验证混合shuffle在批处理模式下执行
validateHybridShuffleExecuteInBatchMode();
// 根据group name,为每个 JobVertex 指定所属的 SlotSharingGroup
// 以及针对 Iteration的头尾设置 CoLocationGroup
setSlotSharingAndCoLocation();
//设置托管内存分数
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id -> streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
// 配置 checkpoint
configureCheckpointing();
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
final Map<String, DistributedCache.DistributedCacheEntry> distributedCacheEntries =
JobGraphUtils.prepareUserArtifactEntries(
streamGraph.getUserArtifacts().stream()
.collect(Collectors.toMap(e -> e.f0, e -> e.f1)),
jobGraph.getJobID());
for (Map.Entry<String, DistributedCache.DistributedCacheEntry> entry :
distributedCacheEntries.entrySet()) {
// 添加用户提供的自定义的文件信息
jobGraph.addUserArtifact(entry.getKey(), entry.getValue());
}
// set the ExecutionConfig last when it has been finalized
try {
// 将 StreamGraph 的 ExecutionConfig 序列化到 JobGraph 的配置中
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
} catch (IOException e) {
throw new IllegalConfigurationException(
"Could not serialize the ExecutionConfig."
+ "This indicates that non-serializable types (like custom serializers) were registered");
}
jobGraph.setJobConfiguration(streamGraph.getJobConfiguration());
//在顶点名称中添加顶点索引前缀
addVertexIndexPrefixInVertexName();
//设置顶点描述
setVertexDescription();
// Wait for the serialization of operator coordinators and stream config.
try {
//等待运算符coordinator和流配置的序列化。
FutureUtils.combineAll(
vertexConfigs.values().stream()
.map(
config ->
config.triggerSerializationAndReturnFuture(
serializationExecutor))
.collect(Collectors.toList()))
.get();
//等待序列化期货并更新作业顶点
waitForSerializationFuturesAndUpdateJobVertices();
} catch (Exception e) {
throw new FlinkRuntimeException("Error in serialization.", e);
}
if (!streamGraph.getJobStatusHooks().isEmpty()) {
//设置作业状态钩子
jobGraph.setJobStatusHooks(streamGraph.getJobStatusHooks());
}
return jobGraph;
}StreamingJobGraphGenerator#createJobGraph 函数的逻辑也很清晰,首先为所有节点生成一个唯一的hash id,如果节点在多次提交中没有改变(包括并发度、上下游等),那么这个id就不会改变,这主要用于故障恢复。这里我们不能用 StreamNode.id 来代替,因为这是一个从 1 开始的静态计数变量,同样的 Job 可能会得到不一样的 id。(如下代码示例的两个job是完全一样的,但是source的id却不一样了)。然后就是最关键的 chaining 处理,和生成JobVetex、JobEdge等。之后就是写入各种配置相关的信息。
// 范例1:A.id=1 B.id=2
DataStream<String> A = ...
DataStream<String> B = ...
A.union(B).print();
// 范例2:A.id=2 B.id=1
DataStream<String> B = ...
DataStream<String> A = ...
A.union(B).print();我们先来看一下,Flink 是如何确定两个 Operator 是否能够被 chain 到同一个节点的:
public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) {
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
//下游节点只有一个输入
return downStreamVertex.getInEdges().size() == 1 && isChainableInput(edge, streamGraph);
}
//是可链化的输入
private static boolean isChainableInput(StreamEdge edge, StreamGraph streamGraph) {
StreamNode upStreamVertex = streamGraph.getSourceVertex(edge);
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
if (!(streamGraph.isChainingEnabled()
//是同一个插槽共享组
&& upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
//运算符是否可链化
&& areOperatorsChainable(upStreamVertex, downStreamVertex, streamGraph)
//分区程序和exchange模式是否可链化
&& arePartitionerAndExchangeModeChainable(
edge.getPartitioner(), edge.getExchangeMode(), streamGraph.isDynamic()))) {
return false;
}
// check that we do not have a union operation, because unions currently only work
// through the network/byte-channel stack.
// we check that by testing that each "type" (which means input position) is used only once
for (StreamEdge inEdge : downStreamVertex.getInEdges()) {
if (inEdge != edge && inEdge.getTypeNumber() == edge.getTypeNumber()) {
return false;
}
}
return true;
}
public boolean isSameSlotSharingGroup(StreamNode downstreamVertex) {
return (slotSharingGroup == null && downstreamVertex.slotSharingGroup == null)
|| (slotSharingGroup != null
&& slotSharingGroup.equals(downstreamVertex.slotSharingGroup));
}
static boolean areOperatorsChainable(
StreamNode upStreamVertex, StreamNode downStreamVertex, StreamGraph streamGraph) {
StreamOperatorFactory<?> upStreamOperator = upStreamVertex.getOperatorFactory();
StreamOperatorFactory<?> downStreamOperator = downStreamVertex.getOperatorFactory();
if (downStreamOperator == null || upStreamOperator == null) {
return false;
}
// yielding operators cannot be chained to legacy sources
// unfortunately the information that vertices have been chained is not preserved at this
// point
if (downStreamOperator instanceof YieldingOperatorFactory
&& getHeadOperator(upStreamVertex, streamGraph).isLegacySource()) {
return false;
}
// we use switch/case here to make sure this is exhaustive if ever values are added to the
// ChainingStrategy enum
boolean isChainable;
switch (upStreamOperator.getChainingStrategy()) {
case NEVER:
isChainable = false;
break;
case ALWAYS:
case HEAD:
case HEAD_WITH_SOURCES:
isChainable = true;
break;
default:
throw new RuntimeException(
"Unknown chaining strategy: " + upStreamOperator.getChainingStrategy());
}
switch (downStreamOperator.getChainingStrategy()) {
case NEVER:
case HEAD:
isChainable = false;
break;
case ALWAYS:
// keep the value from upstream
break;
case HEAD_WITH_SOURCES:
// only if upstream is a source
isChainable &= (upStreamOperator instanceof SourceOperatorFactory);
break;
default:
throw new RuntimeException(
"Unknown chaining strategy: " + downStreamOperator.getChainingStrategy());
}
// Only vertices with the same parallelism can be chained.
//只有具有相同并行性的顶点才能被链接。
isChainable &= upStreamVertex.getParallelism() == downStreamVertex.getParallelism();
//是否启用了具有不同最大并行度的运算符的链接
if (!streamGraph.isChainingOfOperatorsWithDifferentMaxParallelismEnabled()) {
isChainable &=
upStreamVertex.getMaxParallelism() == downStreamVertex.getMaxParallelism();
}
return isChainable;
}
@VisibleForTesting
static boolean arePartitionerAndExchangeModeChainable(
StreamPartitioner<?> partitioner,
StreamExchangeMode exchangeMode,
boolean isDynamicGraph) {
if (partitioner instanceof ForwardForConsecutiveHashPartitioner) {
checkState(isDynamicGraph);
return true;
} else if ((partitioner instanceof ForwardPartitioner)
&& exchangeMode != StreamExchangeMode.BATCH) {
return true;
} else {
return false;
}
}只要一条边两端的节点满足上面的条件,那么这两个节点就可以被串联在同一个 JobVertex 中。接着来就来看最为关键的函数 setChaining 的逻辑:
// 从source开始建立 node chains 这将递归创建所有JobVertex实例
private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes) {
// we separate out the sources that run as inputs to another operator (chained inputs)
// from the sources that needs to run as the main (head) operator.
//我们将作为另一个运算符 (链接输入) 的输入运行的源与需要作为主 (头) 运算符运行的源分开。
final Map<Integer, OperatorChainInfo> chainEntryPoints =
buildChainedInputsAndGetHeadInputs(hashes, legacyHashes);
//初始入口点
final Collection<OperatorChainInfo> initialEntryPoints =
chainEntryPoints.entrySet().stream()
.sorted(Comparator.comparing(Map.Entry::getKey))
.map(Map.Entry::getValue)
.collect(Collectors.toList());
// iterate over a copy of the values, because this map gets concurrently modified
//遍历值的副本,因为此映射同时被修改
for (OperatorChainInfo info : initialEntryPoints) {
createChain(
info.getStartNodeId(),
//运算符从位置1开始,因为0用于链接的源输入
1, // operators start at position 1 because 0 is for chained source inputs
info,
chainEntryPoints);
}
}
// 构建node chains,返回当前节点的物理出边
// startNodeId != currentNodeId 时,说明currentNode是chain中的子节点
private List<StreamEdge> createChain(
final Integer currentNodeId,
final int chainIndex,
final OperatorChainInfo chainInfo,
final Map<Integer, OperatorChainInfo> chainEntryPoints) {
Integer startNodeId = chainInfo.getStartNodeId();
if (!builtVertices.contains(startNodeId)) {
// 过渡用的出边集合, 用来生成最终的 JobEdge, 注意不包括 chain 内部的边
List<StreamEdge> transitiveOutEdges = new ArrayList<StreamEdge>();
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
StreamNode currentNode = streamGraph.getStreamNode(currentNodeId);
boolean isOutputOnlyAfterEndOfStream = currentNode.isOutputOnlyAfterEndOfStream();
if (isOutputOnlyAfterEndOfStream) {
outputBlockingNodesID.add(currentNode.getId());
}
// 将当前节点的出边分成 chainable 和 nonChainable 两类
for (StreamEdge outEdge : currentNode.getOutEdges()) {
if (isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
//==> 递归调用
for (StreamEdge chainable : chainableOutputs) {
// Mark downstream nodes in the same chain as outputBlocking
if (isOutputOnlyAfterEndOfStream) {
outputBlockingNodesID.add(chainable.getTargetId());
}
transitiveOutEdges.addAll(
createChain(
chainable.getTargetId(),
chainIndex + 1,
chainInfo,
chainEntryPoints));
// Mark upstream nodes in the same chain as outputBlocking
if (outputBlockingNodesID.contains(chainable.getTargetId())) {
outputBlockingNodesID.add(currentNodeId);
}
}
for (StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
createChain(
nonChainable.getTargetId(),
1, // operators start at position 1 because 0 is for chained source inputs
chainEntryPoints.computeIfAbsent(
nonChainable.getTargetId(),
(k) -> chainInfo.newChain(nonChainable.getTargetId())),
chainEntryPoints);
}
// 生成当前节点的显示名,如:"Keyed Aggregation -> Sink: Unnamed"
chainedNames.put(
currentNodeId,
createChainedName(
currentNodeId,
chainableOutputs,
Optional.ofNullable(chainEntryPoints.get(currentNodeId))));
chainedMinResources.put(
currentNodeId, createChainedMinResources(currentNodeId, chainableOutputs));
chainedPreferredResources.put(
currentNodeId,
createChainedPreferredResources(currentNodeId, chainableOutputs));
OperatorID currentOperatorId =
chainInfo.addNodeToChain(
currentNodeId,
streamGraph.getStreamNode(currentNodeId).getOperatorName());
if (currentNode.getInputFormat() != null) {
getOrCreateFormatContainer(startNodeId)
.addInputFormat(currentOperatorId, currentNode.getInputFormat());
}
if (currentNode.getOutputFormat() != null) {
getOrCreateFormatContainer(startNodeId)
.addOutputFormat(currentOperatorId, currentNode.getOutputFormat());
}
// 如果当前节点是起始节点, 则直接创建 JobVertex 并返回 StreamConfig, 否则先创建一个空的 StreamConfig
// createJobVertex 函数就是根据 StreamNode 创建对应的 JobVertex, 并返回了空的 StreamConfig
StreamConfig config =
currentNodeId.equals(startNodeId)
? createJobVertex(startNodeId, chainInfo)
: new StreamConfig(new Configuration());
tryConvertPartitionerForDynamicGraph(chainableOutputs, nonChainableOutputs);
setOperatorConfig(currentNodeId, config, chainInfo.getChainedSources());
setOperatorChainedOutputsConfig(config, chainableOutputs);
// we cache the non-chainable outputs here, and set the non-chained config later
opNonChainableOutputsCache.put(currentNodeId, nonChainableOutputs);
if (currentNodeId.equals(startNodeId)) {
chainInfo.setTransitiveOutEdges(transitiveOutEdges);
chainInfos.put(startNodeId, chainInfo);
// 如果是chain的起始节点。(不是chain中的节点,也会被标记成 chain start)
config.setChainStart();
config.setChainIndex(chainIndex);
config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());
// 将chain中所有子节点的StreamConfig写入到 headOfChain 节点的 CHAINED_TASK_CONFIG 配置中
config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));
} else {
chainedConfigs.computeIfAbsent(
startNodeId, k -> new HashMap<Integer, StreamConfig>());
config.setChainIndex(chainIndex);
StreamNode node = streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
// 将当前节点的StreamConfig添加到该chain的config集合中
chainedConfigs.get(startNodeId).put(currentNodeId, config);
}
config.setOperatorID(currentOperatorId);
if (chainableOutputs.isEmpty()) {
config.setChainEnd();
}
// 返回连往chain外部的出边集合
return transitiveOutEdges;
} else {
return new ArrayList<>();
}
}setChaining会对source调用createChain方法,该方法会递归调用下游节点,从而构建出node chains。createChain会分析当前节点的出边,根据Operator Chains中的chainable条件,将出边分成chainalbe和noChainable两类,并分别递归调用自身方法。之后会将StreamNode中的配置信息序列化到StreamConfig中。如果当前不是chain中的子节点,则会构建 JobVertex 和 JobEdge相连。如果是chain中的子节点,则会将StreamConfig添加到该chain的config集合中。一个node chains,除了 headOfChain node会生成对应的 JobVertex,其余的nodes都是以序列化的形式写入到StreamConfig中,并保存到headOfChain的 CHAINED_TASK_CONFIG 配置项中。直到部署时,才会取出并生成对应的ChainOperators,具体过程请见理解 Operator Chains。
每一个 operator chain 都会为所有的实际输出边创建对应的 JobEdge,并和 JobVertex 连接:
private void connect(Integer headOfChain, StreamEdge edge, NonChainedOutput output) {
physicalEdgesInOrder.add(edge);
Integer downStreamVertexID = edge.getTargetId();
//上下游节点
JobVertex headVertex = jobVertices.get(headOfChain);
JobVertex downStreamVertex = jobVertices.get(downStreamVertexID);
StreamConfig downStreamConfig = new StreamConfig(downStreamVertex.getConfiguration());
//下游节点增加一个输入
downStreamConfig.setNumberOfNetworkInputs(downStreamConfig.getNumberOfNetworkInputs() + 1);
StreamPartitioner<?> partitioner = output.getPartitioner();
ResultPartitionType resultPartitionType = output.getPartitionType();
checkBufferTimeout(resultPartitionType, edge);
JobEdge jobEdge;
//创建 JobEdge 和 IntermediateDataSet
//根据StreamPartitioner类型决定在上游节点(生产者)的子任务和下游节点(消费者)之间的连接模式
if (partitioner.isPointwise()) {
jobEdge =
downStreamVertex.connectNewDataSetAsInput(
headVertex,
DistributionPattern.POINTWISE,
resultPartitionType,
output.getDataSetId(),
partitioner.isBroadcast());
} else {
jobEdge =
downStreamVertex.connectNewDataSetAsInput(
headVertex,
DistributionPattern.ALL_TO_ALL,
resultPartitionType,
output.getDataSetId(),
partitioner.isBroadcast());
}
// set strategy name so that web interface can show it.
// 设置策略名称,以便web界面可以显示它。
jobEdge.setShipStrategyName(partitioner.toString());
jobEdge.setForward(partitioner instanceof ForwardPartitioner);
jobEdge.setDownstreamSubtaskStateMapper(partitioner.getDownstreamSubtaskStateMapper());
jobEdge.setUpstreamSubtaskStateMapper(partitioner.getUpstreamSubtaskStateMapper());
if (LOG.isDebugEnabled()) {
LOG.debug(
"CONNECTED: {} - {} -> {}",
partitioner.getClass().getSimpleName(),
headOfChain,
downStreamVertexID);
}
}小结※
本文分析了从 StreamGraph 到 JobGraph 之间的转换过程。 JobGraph 的关键在于将多个 StreamNode 优化为一个 JobVertex, 对应的 StreamEdge 则转化为 JobEdge, 并且 JobVertex 和 JobEdge 之间通过 IntermediateDataSet 形成一个生产者和消费者的连接关系。
参考资料:
